Pasjonuję się IT, ekonomią i muzyką. Moim ulubionym językiem jest Java i w niej pracuję na codzień.
Łączenie z internetem nieuchronnie prowadzi nas do udostępniania i dostarczania swoich danych różnym podmiotom. Począwszy od zapisania naszej aktywności w logach naszego dostawcy usług internetowych (ISP), którą mogą badać organy ścigania, skończywszy na różnorodnych portalach społecznościowych i ecommerce, które odwiedzamy.
Dane zostawiamy jak odciski palców, gdy używamy dany przedmiot. Przy umiejętnej analizie, przy wykorzystaniu wiedzy i narzędzi, można zbadać wiele informacji na temat użytkownika.
Aby przybliżyć skalę gromadzenia danych, można przybliżyć statystyki, które są zamieszczone na infografice (rysunek 1). Na chwilę obecną przyrost danych przyjmuje kształt funkcji wykładniczej. Analitycy nie przewidują załamania tej tendencji. Ponad 90% ogółu istniejących danych zostało zgromadzone w przeciągu 2 lat [link do raportu IBM].
W 2012 r. Prognozowano podwojenie danych co dwa lata do roku 2020. W 2020 r. Ilość wytworzonych danych cyfrowych przekroczy 40 zettabajtów, co odpowiada 5 200 gigabajtom na każdego mężczyznę, kobietę i dziecko na ziemi.

Jak przechowywać tak duże zbiory danych? Do czego się mogą przydać? Czy posiadanie ich może być niebezpieczne? Opracowaniem tych problemów zajmują się badania nad Big Data. Ta szeroka dziedzina obejmuje wiele mniejszych sub dziedzin, jak na przykład uczenie maszynowe, technologie blockchain czy rozproszone bazy danych. W tym krótkim referacie jednak nie starczy miejsca na dokładne opracowanie tych zagadnień, zatem zostaną one wyjaśnione zwięźle.
Historia Big Data
Jednym z najstarszych dużych zbiorów danych była biblioteka asyryjskiego króla Assurbanipala. Została ona odkryta w dwóch fazach w czasie prac wykopaliskowych prowadzonych od 1849 roku przez Austena H. Layarda na terenach starożytnej Mezopotamii na wzgórzu Kujundżyk, które kryło w sobie pozostałości pałaców: Sennacheryba i Assurbanipala.
Jej powstanie szacuje się na VII w p.n.e. Nie znano wtedy papieru, przez co wszystkie dane zostały spisane na glinianych tabliczkach. Spisano na nich ówczesne przepisy, ewidencję ludności a także około 5000 dzieł literackich religijnych i naukowych z zakresu prawa, historii, astronomii, matematyki. Kolekcja zawiera łącznie ok. 20 000 glinianych tabliczek z obydwu pałaców.
Biblioteka Assurbanipala jest relatywnie małym zbiorem danych w porównaniu do dzisiejszych zasobów baz danych. Nie należy się dziwić - bariera technologiczna między ówczesnymi czasami a XXI wiekiem jest ogromna. Dawne niezautomatyzowane metody gromadzenia informacji sprawiały, że praca w administracji była trudna i żmudna. Pomimo tego uznałam, że należało o niej wspomnieć, aby zwrócić uwagę na fakt, iż nie jest to nowy termin, a zjawisko istniejące od początku cywilizacji.
Od czasów Assurbanipala minęło wiele wieków, podczas których rozwijano wiedzę o otaczającym nas świecie. Każda dziedzina ma tyle powiązań z drugą, że nie sposób rozpisać się o absolutnie całej historii danej nauki. Należałoby w takiej sytuacji cofnąć się do czasów, gdy odkryto elektryczność, przejść przez dynamiczną historię rozwoju komputerów i ich wydajności, by dopiero móc rozważać nad pełną historią big data. Są jednak takie fakty, które są na tyle ważne, że nie powinno się ich pominąć.
Istotnym przełomem w cyfryzacji danych było wynalezienie w roku 1928 przez Fritza Pfleumera, niemiecko-austriackiego inżyniera, metody przechowywania danych na taśmach magnetycznych. Zasady, które opracował, są nadal używane, a większość danych cyfrowych jest przechowywana tą właśnie metodą na dyskach twardych komputera.
W 1956 przeciętny dysk miał pojemność 5MB. Obecnie pamięci masowe do wykorzystania w serwerach posiadają pojemność do 14TB. Duży przyrost powierzchni dysków w przeciągu 60 lat dał szansę na lepsze i optymalniejsze gromadzenie danych.

W 1997 Michael Cox i David Ellsworth opublikowane "Application-Controlled Demand Paging for Out-of-Core Visualization". Jest to pierwszy artykuł wykorzystujący termin "big data". Praca rozpoczyna się od stwierdzenia:
"Wizualizacja stanowi interesujące wyzwanie dla systemów komputerowych: zbiory danych są na ogół dość duże, obciążając pojemność pamięci głównej, dysku lokalnego, a nawet dysku zdalnego. Nazywamy to problemem dużych zbiorów danych. Gdy zestawy danych nie mieszczą się w pamięci głównej (w rdzeniu) lub gdy nie mieszczą się nawet na dysku lokalnym, najczęstszym rozwiązaniem jest zdobycie większej ilości zasobów. "
W 1998 roku została założona spółka Google Inc. przez dwóch doktorantów Uniwersytetu Stanforda, Amerykanina Larry'ego Page'a i Rosjanina Siergieja Brina. Opracowali oni nowatorską metodę analizy powiązań hipertekstowych – algorytm BackRub, potem przemianowany na PageRank – którą wykorzystali w swoim prototypie wyszukiwarki internetowej.
Korzystając z Big Data, korporacja musi rozprawiać się z bilionami danych znajdujących się w sieci i przeanalizować miliardy zachowań ludzi w internecie, aby dokładnie wiedzieć gdzie znaleźć odpowiedzi na zapytania użytkowników. Obecnie bazy danych Google stanowią ponad 1 milion petabajtów danych. Analizują także ponad 24 petabajty danych dziennie, co stanowi tysiąc razy więcej niż wszystkie materiały wydrukowane kiedykolwiek w Bibliotece Kongresu Stanów Zjednoczonych.
Łatwo jest uwierzyć, że istnienie dużych zbiorów danych nie jest bardziej odległe niż kilka ostatnich lat, a analiza danych stała się kluczowa dla przedsiębiorstw dopiero w ostatnich kilku dekadach. To prawda, że stanowisko biznesowe w zakresie analizy danych uległo przesunięciu w czasie; Im bardziej dostępne są dane, tym ważniejsze dla firm jest znalezienie sposobu konwersji danych na wzbogacone źródła informacji biznesowych, dzięki czemu zyskują przewagę nad konkurencją. Wiele firm trafnie wykorzystuje dane jako aktywa biznesowe, ponieważ są integralną częścią prowadzenia działalności gospodarczej.
Czym są zatem Big Data?
Jedna z pierwszych definicji Big Data została wprowadzona przez M. Cox i D. Ellswortha w 1997 roku. Autorzy traktują Big Data jako duże dane do analizowania, których liczbę należy maksymalizować w celu wydobycia wartości informacyjnych. Inną propozycję definicji wysunął analityk pracujący dla Gartner w 2001 r., ówcześnie META Group (firmy analityczno-doradczej specjalizującej się w technologiach informacyjnych). Oparł ją na koncepcji trzech atrybutów w modelu „3V”.
Big Data charakteryzują atrybuty: objętość (volume), różnorodność (variety), szybkość przetwarzania (velocity) [Doug 2001]. Następnie w roku 2012 firma Gartner wprowadziła dodatkowe dwa wymiary odnoszące się do dużych danych: zmienność (variability) i złożoność (complexity).

Big Data należy rozumieć jako techniki łączące rozwiązania z wielu obszarów charakteryzujących dane.
- Szybkość – dane napływające szybko, strumieniowo, które w związku z procesami
biznesowymi wymagają dodatkowej mocy obliczeniowej do ich analizy w
czasie rzeczywistym. - Różnorodność – dane pochodzą z wielu źródeł i często występują w różnych formatach i są zapisywane za pomocą różnych modeli oraz wyrażane w dowolnej formie, np.: liczbowo, tekst, obrazowo, dźwiękowo, oraz generowane w różny sposób.
- Zmienność – dane, których natężenie jest zmienne w czasie, a przepływy danych
podlegają okresowym cyklom i trendom, a także szczytom, co związane jest
również z dynamiką procesów i zmian gospodarczych czy politycznych. - Złożoność – złożoność danych jest ściśle związana z różnorodnością (semi-structured, „quazi” structured, unstructured), które należy zintegrować w celu odkrycia nieznanych relacji, powiązań i hierarchii. Do danych strukturalnych należą: numery telefonów, pesel, numer karty kredytowej. Dane o mieszanej strukturze to np. pliki XML, e-mail, Elektroniczna Wymiana Danych (Electronic Data Interchange, EDI). Natomiast dane niestrukturalne to: dokumenty, pliki wideo i zdjęcia.
- Wartość – unikatowa wartość informacyjna ukryta w dużych i złożonych strukturach danych, dająca możliwość wyciągania nowych wniosków, które następnie przyczyniają się do wzrostu efektywności działania organizacji na różnych płaszczyznach.
Użyteczność i wykorzystanie Big Data
S. Parise i in. określają cztery główne kierunki wykorzystania analiz dużych zbiorów danych:
- Analizy społeczne (social analysis)
- Podejmowanie decyzji (decision science).
- Podnoszenie efektywności i skuteczności (performance management).
- Eksploracja danych (data exploration).
Big Data pozwala niemal natychmiast odpowiedzieć na skomplikowane problemy biznesowe oraz naukowe. Dane mogą być nie tylko naukową wiedzą, ale także informacją biznesową, dzięki której można zyskać wiele wymiernych korzyści związanych z obniżeniem kosztów działalności, organizacji oraz zarządzania.
Duże strumienie kapitału, skierowane w sektor big data, mogą pozwolić na uzyskanie sukcesu w biznesie oraz osiągnięć naukowych. Jest to niezwykły wymiar, który umożliwia dokonać nowych, nieznanych dotąd operacji. Dostarcza on ogromne możliwości informacyjne.
Prawidłowo zinterpretowane dane przez specjalistów, mogą wpłynąć na optymalizację wielu procesów w gospodarce, w polityce czy ochronie środowiska. Ilość różnych dziedzin, w których można wykorzystać big data, jest ogromna. Nie należy jednak do każdego wykorzystania podchodzić jednakowo, a wypracować najbardziej optymalny system zarządzania dla danej branży.
Trudno zliczyć wszystkie możliwe sektory, w których można wykorzystać naukę o danych, jednak z pewnością można wymienić główne obszary jak na przykład: usługi bankowe, finanse, edukacja, logistyka w transporcie, modelowanie środowiska, oszczędzanie zasobów.

Zarządzanie Big Data i narzędzia
Zarządzanie dużymi danymi to szeroka koncepcja, która obejmuje zasady, procedury i technologie wykorzystywane do gromadzenia, przechowywania, zarządzania, organizacji, administrowania i dostarczania dużych repozytoriów danych. Może obejmować oczyszczanie danych, migrację, integrację i przygotowanie do użycia w raportach i analizach.
Big data jest ściśle związane z ideą zarządzania cyklem życia danych (DLM). Jest to szeroka koncepcja określania, które informacje powinny być przechowywane w bazach danych organizacji, a także kiedy dane można bezpiecznie usunąć.
Nad zespołem data scientists spoczywa ogromna odpowiedzialność wynikająca z dbania o bezpieczeństwo danych, umiejętnego zarządzania. Istotnym jest posiadanie szerokiej wiedzy z zakresu ekonomii, matematyki, statystyki oraz informatyki, a w szczególności programowania i zarządzania bazami danych. Konieczna jest także umiejętność korzystania z wielu narzędzi przygotowanych do analityki danych. Część z nich jest dostępna jako wolne oprogramowanie, z którego może skorzystać każdy zainteresowany. Jest to zaletą dla szkół oraz samouków, którzy chcą się rozwijać w zakresie big data. Także wiele popularnych przedsiębiorstw, jak na przykład Adobe czy LinkedIn, wykorzystuje Apache Hadoop, który jest opensource.
Istnieją także usługi komercyjne, które udostępniają całe wachlarze usług do zarządzania danymi. Należą do nich na przykład Azure czy AWS.

Microsoft Azure to ciągle rozwijający się zestaw usług w chmurze, który ułatwia sprostanie wyzwaniom biznesowym. Zapewnia swobodę tworzenia i wdrażania aplikacji oraz zarządzania nimi w ogromnej, globalnej sieci przy użyciu wybranych narzędzi i struktur.
Amazon Web Services (AWS) to bezpieczna platforma usług w chmurze oferująca moc obliczeniową, przechowywanie baz danych, dostarczanie treści i inne funkcje, które pomagają firmom skalować się i rozwijać. Rozwiązania oparte na chmurze obliczeniowej AWS pozwalają tworzyć zaawansowane aplikacje o zwiększonej elastyczności, skalowalności i niezawodności.
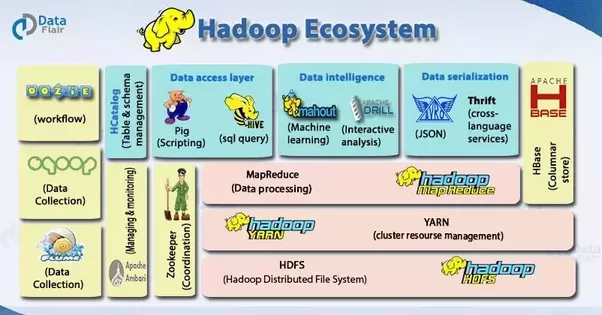
Jedną z ciekawych alternatyw dla komercyjnych platform zarządzania danymi jest Hadoop, otwarte oprogramowanie stworzone przez fundację Apache, która stworzyła m.in. także narzędzia Apache Spark (framework do obliczeń rozproszonych), Apache Storm (przetwarzanie strumieniowe), Kafka (message broker). Dlaczego warto zwrócić uwagę na Hadoop?
- Zdolność do szybkiego przechowywania i przetwarzania ogromnych ilości danych.
- Zoptymalizowana moc obliczeniowa - model obliczeń rozproszonych Hadoop szybko przetwarza duże ilości danych.
- Odporność na awarie. Jeśli węzeł ulegnie awarii, zadania są automatycznie przekierowywane do innych węzłów, aby upewnić się, że przetwarzanie rozproszone nie zakończy się niepowodzeniem. Wiele kopii wszystkich danych jest zapisywane automatycznie.
- Elastyczność. W przeciwieństwie do tradycyjnych relacyjnych baz danych, nie trzeba przygotowywać danych przed ich zapisaniem.
- Platforma open-source jest darmowa i wykorzystuje sprzęt do przechowywania dużych ilości danych.
- Skalowalność. Można łatwo rozbudować swój system, aby obsługiwać więcej danych przez proste dodawanie węzłów.
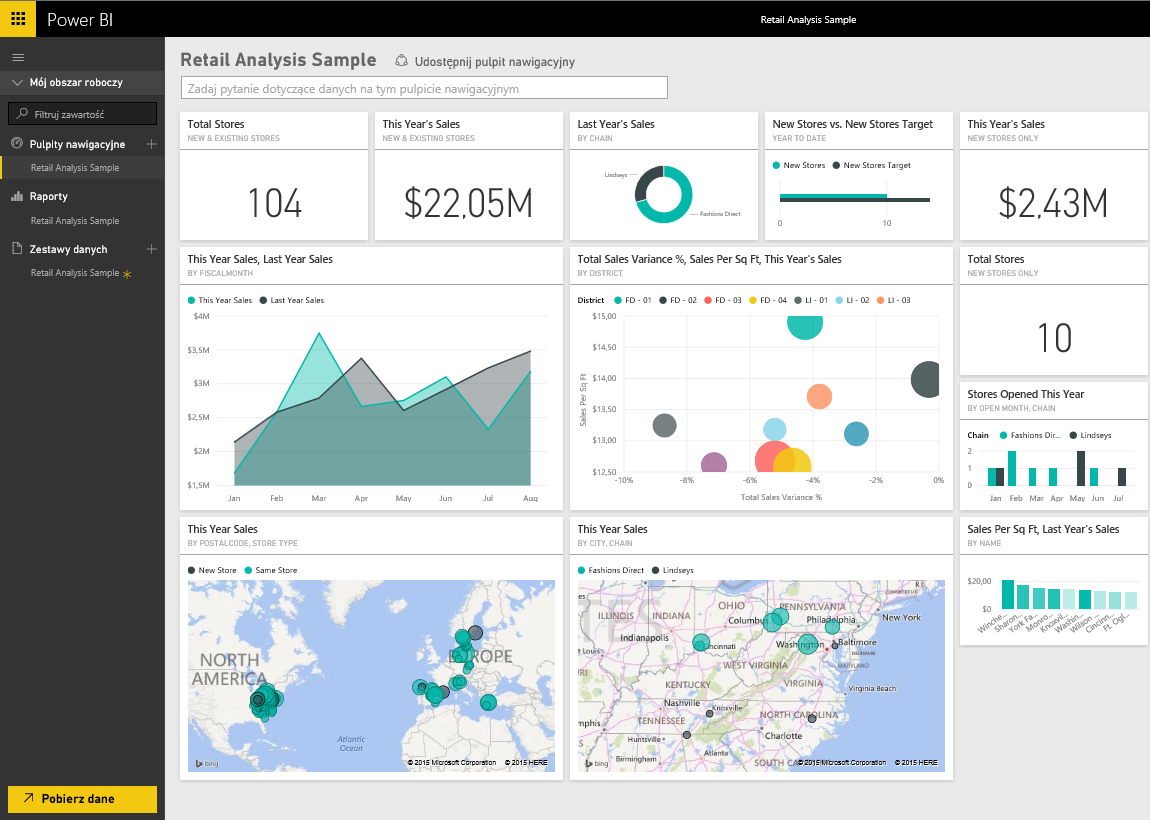
Do wizualizacji danych przyjemnym i łatwym w obsłudze oprogramowaniem jest produkt Microsoftu - PowerBI. Pozwala on przechwytywać dane z baz danych (np mysql, XML, mongoDB) i przedstawiać je w formie kolorowych wykresów.
Bibliografia:
https://www.ibm.com/analytics/hadoop/big-data-analytics
http://www.ce.uw.edu.pl/pliki/pw/3-2017_grabowska.pdf
http://www.blog.intracare.pl/narzedzia-analityczne-big-data/
https://www.evl.uic.edu/cavern/rg/20040525_renambot/Viz/parallel_volviz/paging_outofcore_viz97.pdf
Julia Glaszka
julia.anna.glaszka@interia.pl
Tagi


